Hosting AI Model Mistral 7B on Linux without GPU and Query from React Component.
Why pay for AI tokens when you can self host on your laptop.
Mistral 7B is a powerful AI model that you can set up and run on a Linux computer without needing a special graphics card, known as a GPU. This guide will explain in simple terms how to prepare your computer, install the necessary software, and start using Mistral 7B. You'll learn about the tools you need, the steps to follow, and some tips to make sure everything works smoothly. Even if you're new to working with AI or don't have a GPU, this introduction will help you get started with hosting Mistral 7B on your own Linux system.
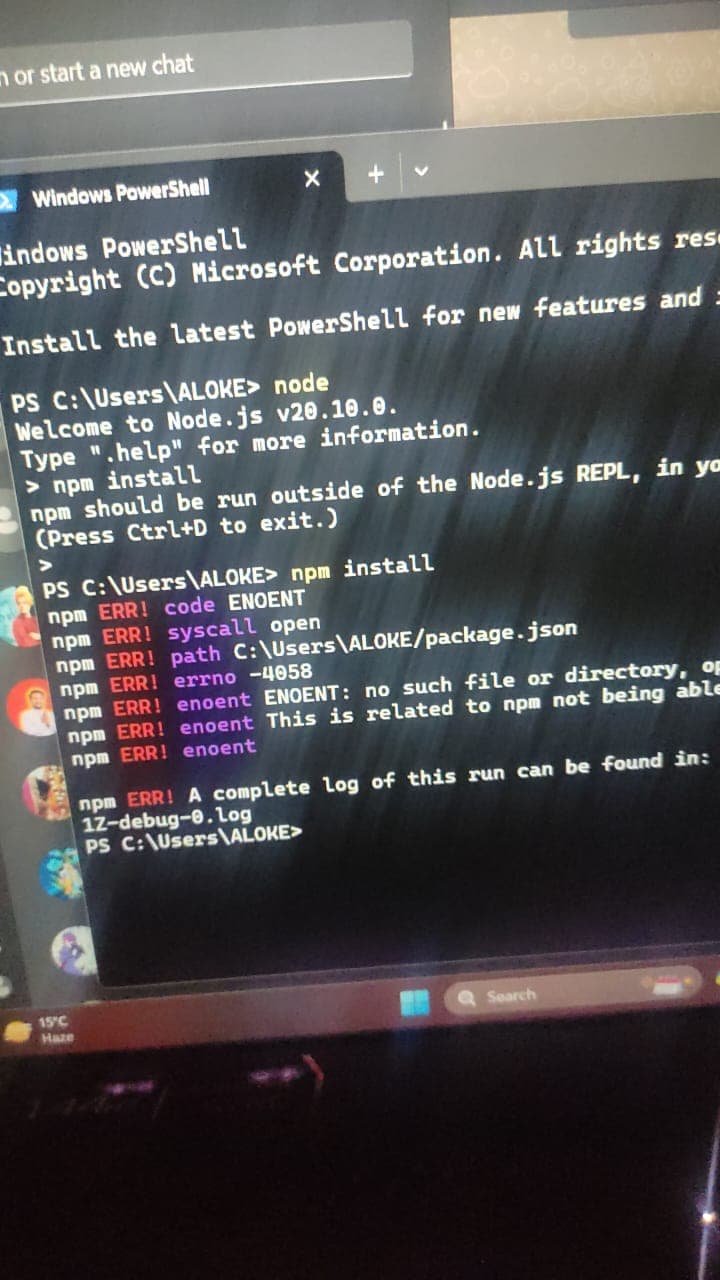
We need LLM inference software that can run our model after we download it locally on our PC/Laptop. llama.cpp is a software that enables us to do that. It's available as a C/C++ source on GitHub so we need to clone and build it before use.
If the C/C++compiler toolchain is not installed then install it with
sudo apt install make gcc g++
then clone and make
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp/
make
the compiling should start. let it finish

Now that we have the inference software ready let's download the model. We choose Mistral-7B-Instruct-v0.2 but it can be any model of choice. We need the model in GGUF format so head to the Huggingface website to download the required model.
https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF

I recommend using the huggingface-hub Python library:
pip3 install huggingface-hub
Download our model file. Should be around 7GB approx so it will take some time to download.
cd models
huggingface-cli download TheBloke/Mistral-7B-v0.1-GGUF mistral-7b-v0.1.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
create a system prompt file system_prompt.json
nano ~/llama.cpp/system_prompt.json
with content for the prompt
{
"prompt": "You are a PC Configuration Assitant, There are four PC types available Epic Extreme Power v2 ,Budget Friend,Speed King,Balance Perfect according to Speed Budget and Power requirement. Select one based on user requirement and recommend only one. Always, Repeat Always In the last line add name of Pc Type in last line after a :\nUser:",
"anti_prompt": "User:",
"assistant_name": "Assistant:"
}
Run the HTTP server that will provide us with a completion API. Note: adjust your current working directory according to your PC.
/root/llama.cpp/server -spf /root/llama.cpp/system_prompt.json --host 0.0.0.0 -m /root/llama.cpp/models/mistral-7b-instruct-v0.2.Q8_0.gguf
Now the HTTP server is running on port 8080

You may additionally need to create this as a service so it runs in the background.
If you have a firewall enable port 8080 to accept all traffic.
opening http://localhost:8080 should show this screen implying success. You can use this screen for debugging and testing the model.

Using this in a React.js component.
Add two react components from https://github.com/honeydreamssoftwares/llama-cpp-react
//completion.tsx
interface Params {
api_key?: string;
n_predict: number,
stream: boolean
}
interface Config {
controller?: AbortController;
api_url?: string;
}
interface CompletionParams extends Params {
prompt: string;
}
interface EventError {
message: string;
code: number;
type: string;
}
interface GenerationSettings {
n_ctx: number;
n_predict: number;
model: string;
seed: number;
temperature: number;
dynatemp_range: number;
dynatemp_exponent: number;
top_k: number;
top_p: number;
min_p: number;
tfs_z: number;
typical_p: number;
repeat_last_n: number;
repeat_penalty: number;
presence_penalty: number;
frequency_penalty: number;
penalty_prompt_tokens: string[];
use_penalty_prompt_tokens: boolean;
mirostat: number;
mirostat_tau: number;
mirostat_eta: number;
penalize_nl: boolean;
stop: string[];
n_keep: number;
n_discard: number;
ignore_eos: boolean;
stream: boolean;
logit_bias: boolean[];
n_probs: number;
min_keep: number;
grammar: string;
samplers: string[];
}
interface EventData {
content: string;
id_slot: number;
stop: boolean;
model: string;
tokens_predicted: number;
tokens_evaluated: number;
generation_settings: GenerationSettings;
prompt: string;
truncated: boolean;
stopped_eos: boolean;
stopped_word: boolean;
stopped_limit: boolean;
stopping_word: string;
tokens_cached: number;
timings: {
prompt_n: number;
prompt_ms: number;
prompt_per_token_ms: number;
prompt_per_second: number;
predicted_n: number;
predicted_ms: number;
predicted_per_token_ms: number;
predicted_per_second: number;
};
}
interface SSEEvent {
event?: unknown;
data?: EventData;
id?: string;
retry?: number;
error?: EventError; // Define a more specific error interface if possible
[key: string]: unknown;
}
type ParsedValue = string | EventData | EventError | undefined;
export async function* llama(prompt: string, params: Params, config: Config = {}): AsyncGenerator<SSEEvent, string, undefined> {
const controller = config.controller ?? new AbortController();
const api_url = config.api_url ?? "";
const completionParams: CompletionParams = {
...params,
prompt
};
const response = await fetch(`${api_url}/completion`, {
method: 'POST',
body: JSON.stringify(completionParams),
headers: {
'Connection': 'keep-alive',
'Content-Type': 'application/json',
'Accept': 'text/event-stream',
...(params.api_key ? { 'Authorization': `Bearer ${params.api_key}` } : {})
},
signal: controller.signal,
});
if(response.body===null){
return "No response";
}
const reader = response.body.getReader();
const decoder = new TextDecoder();
let content = "";
let leftover = "";
try {
let cont = true;
while (cont) {
const result = await reader.read();
if (result.done) {
break;
}
const text = leftover + decoder.decode(result.value);
const endsWithLineBreak = text.endsWith('\n');
const lines = text.split('\n');
if (!endsWithLineBreak) {
leftover = lines.pop() ?? "";
} else {
leftover = "";
}
for (const line of lines) {
const match = /^(\S+):\s(.*)$/.exec(line);
if (match) {
let key = match[1];
const value:ParsedValue = match[2];
const event: Partial<SSEEvent> = {};
if (key === "data" || key === "error") {
// Attempt to parse JSON for data or error fields
try {
if(value){
// eslint-disable-next-line @typescript-eslint/no-unsafe-assignment
event[key] = JSON.parse(value);
}
} catch {
event[key] = value as unknown as EventData & EventError; // Use raw value if JSON parsing fails
}
} else {
if(!key){
key='0';
}
event[key] = value;
}
// Specific processing for parsed data
if (key === "data" && event.data) {
content += event.data.content;
yield event as SSEEvent;
if (event.data.stop) {
cont = false;
break;
}
}
// Handling errors
if (key === "error" && event.error) {
try {
if (event.error.message.includes('slot unavailable')) {
throw new Error('slot unavailable');
} else {
console.error(`llama.cpp error [${event.error.code} - ${event.error.type}]: ${event.error.message}`);
}
} catch(e) {
console.error(`Error parsing error data:`, event.error);
}
}
}
}
}
} catch (e: unknown) {
if (typeof e === "object" && e !== null && "name" in e && (e as { name: string }).name !== 'AbortError') {
console.error("llama error: ", e);
} else if (e instanceof Error) {
// This checks if it's an Error object which is more specific and safer
console.error("llama error: ", e.message);
} else {
// Handle cases where error is not an object or unexpected type
console.error("Unexpected error type:", e);
}
throw e;
} finally {
controller.abort();
}
return content;
}
streamedcontent.tsx is the main entry component.
Note: Replace api_url with your AI Backend from llama.cpp
//streamedcontent.tsx
import React, { useState } from 'react';
import { llama } from './completion';
// Define interfaces for expected data types
interface StreamedContentComponentProps {
onPcTypeRecommended: (pcType: string) => void;
}
// Main component definition using React.FC (Functional Component)
const StreamedContentComponent: React.FC<StreamedContentComponentProps> = ({ onPcTypeRecommended }) => {
const [messages, setMessages] = useState<string>(""); // State for storing message strings
const [loading, setLoading] = useState<boolean>(false); // State to track loading status
// Handler for changes in text input, assuming you want to capture input for the llama function
const handleQueryChange = (event: React.ChangeEvent<HTMLInputElement>) => {
setMessages(event.target.value);
};
// Asynchronously fetch or process data, abstracted into its own function for clarity
const fetchStreamedContent = async (query: string) => {
console.log("fetching...",query);
const params = {
n_predict: 512,
stream: true,
};
//Replace with your AI Backend from llama.cpp
const config = {
api_url: 'http://localhost:8080'
};
try {
let newContent="";
for await (const event of llama(query, params, config)) {
if (event.data?.content) {
// Append new content to existing messages
newContent += event.data.content;
setMessages(currentMessages => currentMessages + event.data?.content );
}
if (event.error) {
throw new Error(event.error.message);
}
if (event.data && event.data.stop) {
pcRecommended(newContent);
console.log("Stop received",event.data);
break; // Exit loop if stop signal is received
}
}
} catch (error) {
console.error('Error consuming events:', error);
}
};
const pcRecommended = (currentMessages: string) => {
console.log("pcRecommended filtering...",currentMessages);
const lastColonIndex = currentMessages.lastIndexOf(':');
if (lastColonIndex >= 0) {
let pcType = currentMessages.substring(lastColonIndex + 1).trim();
if (pcType.endsWith('.')) {
pcType = pcType.slice(0, -1).trim();
}
pcType = pcType.replace(/[.,;]$/g, '').trim();
onPcTypeRecommended(pcType);
}
};
// Button click handler that triggers the asynchronous operation
const handleAskClick = () => {
if (!messages.trim()) return; // Prevent running with empty query
setLoading(true); // Set loading true when the process starts
void fetchStreamedContent(messages).finally(() => {
setLoading(false); // Reset loading state when the process completes or fails
});
};
return (
<div className="flex flex-col items-center justify-center space-y-4">
<input
type="text"
onChange={handleQueryChange}
className="w-full rounded-lg border border-gray-300 bg-gray-50 p-4 text-sm focus:border-blue-500 focus:ring-blue-500 dark:border-gray-600 dark:bg-gray-700 dark:text-white"
placeholder="Ask AI"
/>
<button
onClick={handleAskClick}
disabled={loading}
className="px-4 py-2 bg-blue-500 text-white rounded hover:bg-blue-600 disabled:bg-blue-300"
>
{loading ? "Thinking..." : "Ask"}
</button>
<div className="w-full p-4 bg-gray-100 rounded shadow">
{messages.split("\n").map((message, index) => (
<p key={index}>{message}</p>
))}
</div>
</div>
);
};
export default StreamedContentComponent;
Using the component.
In main App.tsx include the StreamedContentComponent
//App.tsx
import StreamedContentComponent from './components/streamedcontent'
import './App.css'
function App() {
const onPcTypeRecommended=(pc:string)=>{
console.log("filtering...",pc);
//Filter logic here
}
return (
<div className="min-h-screen bg-gray-100">
<nav className="bg-white shadow">
<div className="max-w-7xl mx-auto px-4 sm:px-6 lg:px-8">
<div className="flex justify-between h-16">
<div className="flex">
<div className="flex-shrink-0 flex items-center">
LLAMA.cpp Selfhosting Demo
</div>
</div>
<div className="hidden sm:flex sm:items-center sm:ml-6">
<a href="#" className="text-gray-800 hover:text-gray-600 px-3 py-2 rounded-md text-sm font-medium">Home</a>
<a href="#" className="text-gray-800 hover:text-gray-600 px-3 py-2 rounded-md text-sm font-medium">Features</a>
<a href="#" className="text-gray-800 hover:text-gray-600 px-3 py-2 rounded-md text-sm font-medium">About</a>
</div>
</div>
</div>
</nav>
<main className="py-10">
<div className="w-96 mx-auto">
<div className="bg-white overflow-hidden shadow-sm sm:rounded-lg">
<div className="p-6 bg-white border-b border-gray-200">
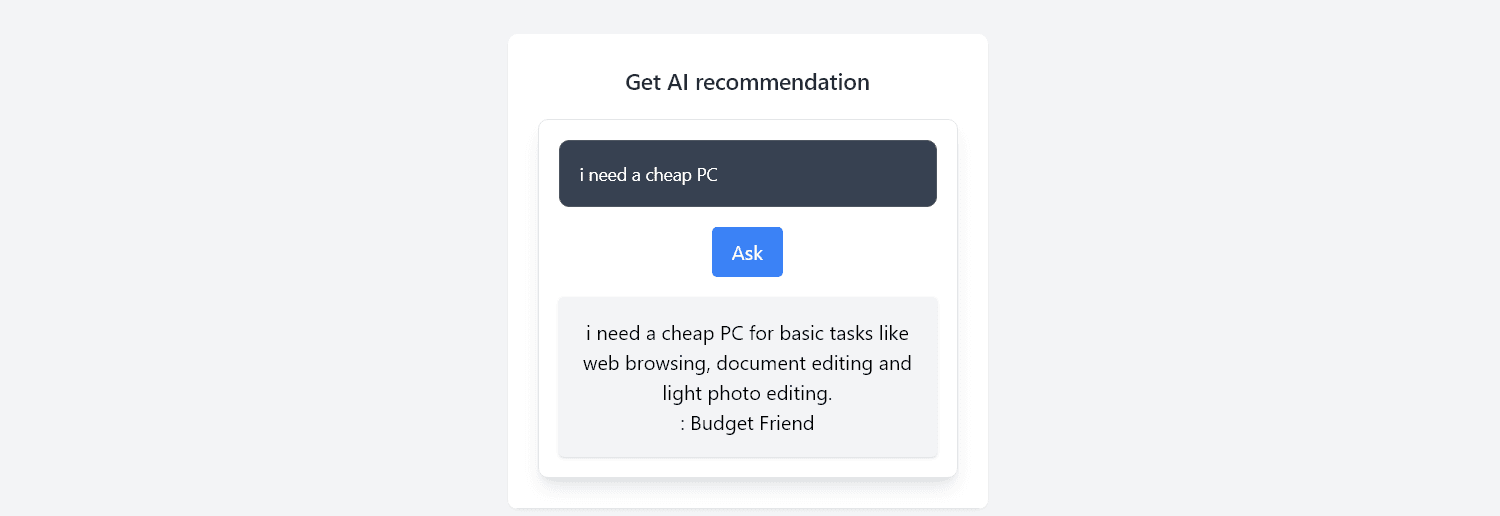
<h3 className="text-lg font-semibold text-gray-800 mb-4">Get AI recommendation</h3>
<div className="p-4 border rounded-lg shadow-lg bg-white">
<StreamedContentComponent onPcTypeRecommended={onPcTypeRecommended}></StreamedContentComponent>
</div>
</div>
</div>
</div>
</main>
</div>
)
}
export default App
Run dev command
npm run dev
Open http://localhost:5173 and ask your question.

Now that this react component can be used anywhere in your project with a self-hosted AI model, it is time to move to cloud-hosted models for scalability. Stay tuned and subscribe. bye.
Links
https://github.com/honeydreamssoftwares/llama-cpp-react
https://github.com/ggerganov/llama.cpp/tree/master/examples/server
Note: Multiple types of models are supported check out llama.cpp GitHub for the list and fine-tuning instructions.